The occurrence of some Incidents is, for all practical purposes, unavoidable. Computer equipment and telecommunications lines fail occasionally. Many other Incidents are caused, not by random failures, but by errors somewhere in organisations' increasingly complex IT infrastructures. Even anticipated failures of computing or telecommunications equipment can increase in impact to unacceptable levels because of an error in a vendor product.
Reactive Problem control (Figure 6.1) is concerned with identifying the real underlying causes of Incidents in order to prevent future recurrences. The three phases involved in the (reactive) Problem control process are:
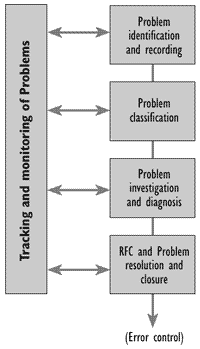
Figure 6.1 - Problem control
When the root cause is detected the error control process begins.
Problem identification takes place when:
It should be noted that some Problems may be identified by personnel outside the Problem Management team, e.g. by Capacity Management. Regardless, all Problems should be notified and recorded via the Problem Management process. Much of the Availability Management process is concerned with the detection and avoidance of Problems and Incidents to the IT infrastructure; a synergy between the two areas is thus an invaluable aid to improving service quality.
Tips:
Problem records need to be recorded in a database (ideally the CMDB) and are very similar to Incident records. They usually exclude some of the standard Incident data (e.g. User data) that is inappropriate. However, Problem records should be linked to all associated Incident records. The solution and Work-arounds of Incidents should be recorded in the relevant Problem records for others to access should other related Incidents occur.
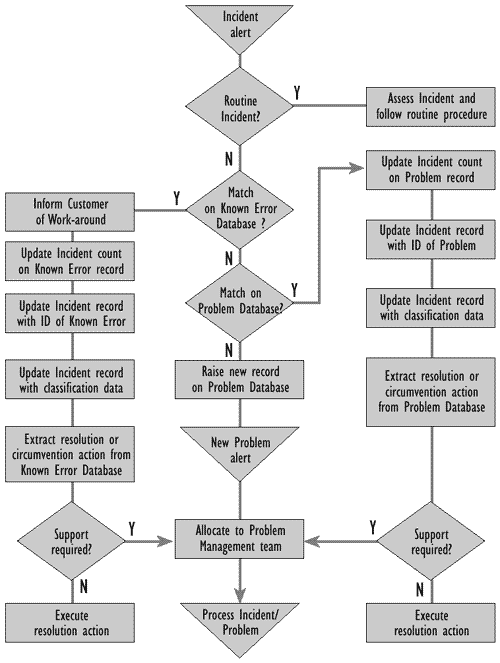
Figure 6.2 - Incident-matching process flow
The process of Problem identification, illustrated in Figure 6.2 includes the basic classification of Problems. Data on affected CIs should be accurately appended to this basic classification data. Ideally, these CIs are the lowest level of item capable of discrete amendment - for example, a module of applications code or hardware component. Identification of a Problem CI to this level is, however, often impossible at the Problem identification stage.
When a Problem is identified, the amount of effort required to detect and recover the failing CI(s) has to be determined. Therefore it is important to be aware of the impact of the Problem on existing service levels. This process is known as 'classification'. In practice, support effort is allocated to only a small proportion of Problems linked to a single Incident.
The steps involved in Problem classification are similar to the steps in classifying Incidents; they are to determine:
Problems are categorised into related groups or domains (e.g. hardware, software, support software, whatever is appropriate). These groups could match the organisational responsibilities, or the User and Customer base, and are the basis for allocating Problems to support staff. Annex 6A gives an example of a simple but effective structure for categorising Problems.
Identification of a new Problem should be followed by an objective analysis of its impact (that is, its effect on the business). The relationships between components in the IT Infrastructure registered in the CMDB can be of great help when determining the impact of a Problem.
Organisations should design their own impact coding system in relation to their business needs. Impact coding is a most useful mechanism for the effective allocation of support effort. The further inclusion of a simple priority rating, subordinate to impact, provides a total control mechanism.
When determining the impact of a Problem, the relations between components in the IT infrastructure registered in the CMDB can be of great help. By interrogating the CMDB, it is possible to identify CIs that are dependent on part of, or identical to, the CI in the IT infrastructure to which the Incident is applied.
Urgency is the extent to which resolution of a Problem or error can bear delay; it should not be confused with priority. Priority indicates the relative order in which a series of items - be they Incidents, Problems, Changes or errors - should be addressed. This will be influenced by considerations of risk and resource availability but is primarily driven by a combination of urgency and impact. Despite a low business impact, something that requires urgent resolution will often be dealt with before something of very high potential business impact but that has lower urgency. It sometimes helps to allocate numerical values to each, in order to derive from them a numerical priority; but, as with all Service Management, such numbers should be modified by human common sense and business awareness. However, a useful and simple starting point is to assign numerical values from 1 to 4 to each of urgency and impact and sum these for any one Problem to give a relative priority. That done, an organisation should monitor and examine critically the resulting priorities and monitor the function to reflect their requirements. Both 'urgency' and 'priority' are listed in Appendix A (Glossary of Terms). Aspects influencing urgency are, for example:
Every Incident, Problem and Change will have both an impact on the business services and an urgency:
Tips:
The process of Problem investigation is similar to that of Incident investigation (see Chapter 5) - but the primary objective of each process is significantly different. Incident Management's aim is rapid restoration of service, whereas Problem Management's aim is diagnosis of the underlying cause. Investigation activities should include available Work-arounds for the Incidents related to the Problem, as registered in the Incident record database. Problem Management activities should include updating recommended Work-arounds in the Problem record, to support Incident control.
Diagnosis frequently reveals that the cause of a Problem is not an error in a registered CI (hardware, software item, documentation or procedure) but is procedural. Incorrect release of a version of a program is one example. These situations result in Problem closure with an appropriate categorisation code. Problems of this type do not automatically achieve the formal status of Known Error. To ensure that these Problems are followed up and that action is taken to address them, consider creating a dummy CI record for the offending procedure and re-classifying the Problem as a Known Error, or raise an RFC.
Diagnosis showing the cause to be a fault in a registered CI should automatically change the status of the Problem into a Known Error. At this point the error control system and procedures take over.
As indicated earlier, the objectives of Problem investigation frequently conflict with those of Incident resolution. For example, Problem investigation may require detailed diagnostics data, which is available only when an Incident has occurred; its capture may significantly delay the restoration of normal services. Be sure to liaise closely with Incident control and the computer operations or network control functions to get a balanced view of the right time for such actions.
Literature provides many methods for structural Problem analysis and diagnosis. Some available methods are:
Problem Management should select methods that best fit the organisation's purposes.
The following are points worth remembering in relation to Problem control: