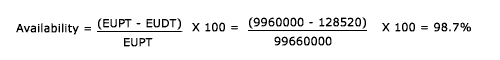8.9.1 Component Failure Impact Analysis
8.9.2 Fault Tree Analysis
8.9.3 CRAMM
8.9.4 Calculating Availability
8.9.5 Calculating the cost of UnAvailability
8.9.6 Developing basic IT Availability
measurement and reporting
8.9.7 Developing business and User
measurement and reporting
8.9.8 Service Outage Analysis
8.9.9 The expanded Incident
'lifecycle'
8.9.10 Continuous improvement
The capability of the Availability Management Process is positively influenced by the range and quality of methods and techniques that are available for deployment and execution within the process.
To provide the reader and prospective process owners with the benefits of established best practice within the field of Availability Management this Section documents a number of proven methods and techniques that can be applied to support key activities within the process. These are: -
The above techniques support the three key facets of Availability Management, namely the planning for Availability, the improvement of Availability and the reporting of Availability.
Table 8.1 provides guidance on which aspect of Availability Management these techniques can be utilised: -
|
Facet Technique |
Availability Planning |
Availability Improvement |
Availability Reporting |
|
|
|
|
|
|
|
|
|
|
|
CRAMM |
|
|
|
|
Calculating Availability |
|
|
|
|
Calculating the Cost of Unavailability |
|
|
|
|
Developing basic IT Availability measurement and reporting |
|
|
|
|
Developing business and User measurement and reporting |
|
|
|
|
|
|
|
|
|
The expanded Incident 'Lifecycle' |
|
|
|
|
Continuous improvement |
|
|
|
|
|
|
|
Table 8.1 - Guidance on the use of Availability Management techniques
![]()
During the 'design for Availability' activities it is necessary to predict and evaluate the impact on IT Service Availability arising from component failures within the proposed IT Infrastructure and service design.
Component Failure Impact Analysis (CFIA) is a relatively simple technique that can be used to provide this information. IBM devised CFIA in the early 1970s with its origins based on hardware design and configuration. However, it is recommended that CFIA be used in a much wider context to reflect the full scope of the IT Infrastructure, i.e. hardware, network, software, application and Users.
Additionally the technique can also be applied to identify impact and dependencies on IT support organisation skills and competencies amongst staff supporting the new IT Service.
This activity is often completed in conjunction with ITSCM.
The output from a CFIA provides vital information to ensure that the Availability and Recovery design criteria for the new IT Service is influenced to prevent or minimise the impact of failure to the business operation and User.
CFIA achieves this by providing and indicating:
The above can also provide the stimulus for input to ITSCM to consider the balance between recovery options and Risk reduction measures, i.e. where the potential business impact is high there is a need to concentrate on high Availability risk reduction measures, i.e. increased resilience or standby systems.
Having determined the IT Infrastructure configuration to be assessed, the first step is to create a grid with CIs on one axis and the IT Services which have a Dependency on the CI on the other. This information should be available from the CMDB. Alternatively this can be built using documented configuration charts and SLAs.
The next step is to perform the following procedure at each intersection point in the grid:
Figure 8.12 contains a completed grid for the configuration shown.
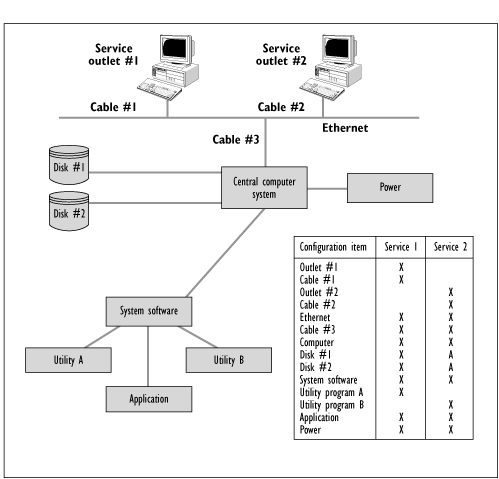
Figure 8.12 - Sample configuration and basic CFIA grid
Having built the grid, CIs that have a large number of Xs are critical to many services and can result in high impact should the CI fail. Equally, IT Services that have high counts of Xs are complex and are vulnerable to failure.
This basic approach to CFIA can provide valuable information in quickly identifying single points of failure, IT Services at risk from CI failure and what alternatives are available should CI fail.
It should also be used to assess the existence and validity of recovery procedures for the selected CIs.
The above example assumes common Infrastructure supporting multiple IT Services. The same approach can be used for a single IT Service by mapping the component CIs against the vital Business functions and Users supported by each component, thus understanding the impact of a component failure on the business and User. This approach is illustrated in Table 8.2.
| Configuration item | VBF |
End Users Impacted |
| Power | All |
1,000 |
| Central computer | All |
1,000 |
| Applications | All |
1,000 |
| Disk # 1 | Payments |
50 |
| Disk # 2 | Orders |
100 |
| Utility A | Enquiry |
25 |
Table 8.2 - CFIA matrix reflecting association between components, VBF and User population
The above approach can be expanded to provide more detailed information and/or to extend the coverage of the CFIA, e.g. data feeds from 3
| Hints and Tips An online IT Service can be impacted by failures in batch processing, e.g. the IT Service is unable to be started due to dependencies on the completion of overnight database updates. A suggested first step prior to undertaking an advanced CFIA is to identify all the software CIs that are essential to the 24hr processing cycle. These would include for example transaction processing subsystems, Network Management subsystems, Security Management subsystems, systems management subsystems such as tape management, silo management, job scheduling. It can also include software CIs that support key IT operational processes such as Incident Management, Problem Management, Change Management and Configuration Management. |
To undertake an advanced CFIA requires the CFIA matrix to be expanded to provide any additional fields required for the more detailed analysis.
Some examples of the additional fields that can be included are as follows:
A detailed CFIA provides additional information that can be used to improve recoverability. While technology design is continually improving as yet no IT CI can ever be considered fail-safe.
A detailed CFIA can provide important information to support the recovery process:
| Example A tape management software failure preventing tape usage may not immediately impact the User. However, the Online Transaction Processing Systems (OLTP) may need to regularly archive system logs to tape. If this cannot be achieved, after a period of time the OLTP may suspend processing directly impacting the User. |
![]()
Fault Tree Analysis (FTA) is a technique that can be used to determine the chain of events that causes a disruption of IT Services. This technique, in conjunction with calculation methods can offer detailed models of Availability.
The main advantages of FTA are:
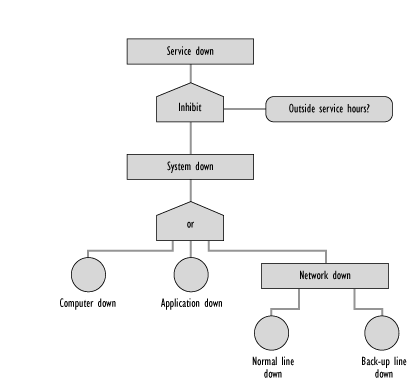
Figure 8.13 - Example Fault Tree
FTA makes a representation of a chain of events using Boolean notation. Figure 8.13 gives an example of a fault tree.
Essentially FTA distinguishes the following events:
These events can be combined using logic operators, i.e.:
The mathematical evaluation of a fault tree is beyond the scope of this Chapter.
![]()
The identification of risks and the provision of justified countermeasures to reduce or eliminate the threats posed by such risks can play an important Role in achieving the required levels of Availability for a new or enhanced IT Service.
Risk Analysis should be undertaken during the design phase for the IT Infrastructure and service to identify:
CRAMM describes a means of identifying justifiable countermeasures to protect Confidentiality, Integrity and Availability of the IT Infrastructure.
The general concepts can be represented by a simple diagram that shows Risk Analysis and Risk Management as being two related but separate activities in Figure 8.14
Figure 8.14 - Risk Analysis Management
Risk Analysis involves the identification and assessment of the level (measure) of the risks calculated from the assessed values of assets and the assessed levels of threats to, and vulnerabilities of, those assets.
Risk Management involves the identification, selection and adoption of countermeasures justified by the identified risks to assets in terms of their potential impact upon services if failure occurs, and the reduction of those risks to an acceptable level.
This approach when applied via a formal method ensures coverage is complete together with sufficient confidence that:
Formal Risk Analysis and Management methods are now an important element in the overall provision of IT Services.
| Hints and Tips CRAMM is a methodology that can be utilised by a number of IT Service Management processes. CRAMM is used and referenced within Chapter 7. 'CRAMM is the UK Government's preferred Risk Analysis and Management method for identifying all the necessary technical and non-technical controls to ensure the security of both current and future information systems processing valuable or protectively marked data.' - UK Security Service |
![]()
This Section describes some of the simple mathematics required to enable component and total Infrastructure Availability to be calculated. This information is needed to help formulate Availability targets for IT components and IT Services. Additionally, these output calculations can also be input to any Availability modelling tools that are available.
The examples provided in this Section are fairly straightforward with the calculations presented sufficient to provide adequate estimates of Availability. Where more detailed estimates of Availability are required it may be necessary to research more complex mathematical calculations. The statistical analysis of Incident data and the forecasting of Availability are a rich study field in many industries outside of IT, i.e. electronics, aviation.
To determine the basic Availability of a given IT Service or component as an Availability percentage (%) the following basic formula can be used:
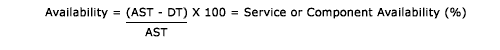
Where: -
AST = Agreed service time
DT = Actual downtime during agreed service time
| Example A 24x7 IT Service requires a weekly 2-hour planned downtime period for application maintenance. Following the completion of the weekly maintenance an application software error occurs which results in 3 hours of unplanned downtime. The weekly Availability for the IT Service in this reporting period is therefore based on the following: The AST should recognise that the planned 2 hr weekly downtime is scheduled. The DT is the 3 hrs of unplanned outage following the application maintenance. The AST value is therefore 24hrs x 7days - 2 hrs planned maintenance = 166 hrs/week. The DT value is therefore the 3 hrs unplanned downtime. The Availability calculation is: - A = 166 - 3 / 166 x 100 = 98.78% |
The Availability percentage for each IT component within the total IT Infrastructure may be different and as such it is necessary to provide a calculation that reflects the total Infrastructure Availability.
The levels of resilience provided positively influence the Availability percentage for the total Infrastructure.
Figure 8.15 illustrates a basic IT Infrastructure configuration where no additional components are provided for resilience. The Availability percentage for this configuration is based on the product of all the individual component Availability percentages.
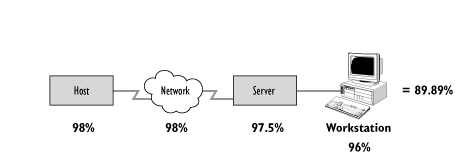
Figure 8.15 - Simple IT Infrastructure configuration
Availability as viewed from the User workstation is therefore calculated as:
Where additional components are added to provide resilience so that the backup component takes over automatically, then the Availability percentage is calculated by multiplying the UnAvailability (reciprocal of Availability) of each component.
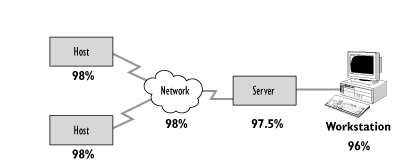
Figure 8.16 - Simple IT configuration with component resilience provided
In the configuration in Figure 8.16, the host component now has a backup component to provide greater resilience. The host component Availability percentage is now recalculated as follows:
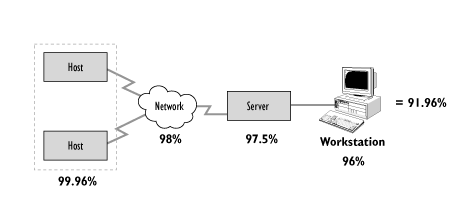
Figure 8.17 - Revised host Availability percentage to reflect additional resilience provided
With the additional resilience provided for the host component, the total Infrastructure Availability can now be calculated as shown in Figure 8.17:
To deliver the required levels of Availability for an IT Service requires focusing on all components within the IT Infrastructure design that underpin the IT Service. The Availability of each individual component influences the overall Availability that can be provided by the total Infrastructure.
When viewing Availability consider the following points:
![]()
To cost justify improvements to the IT Infrastructure that improve Availability, it is necessary to demonstrate how the proposed improvements deliver tangible business benefits.
Where the proposed improvements require a significant re-investment in the IT Infrastructure the benefits often need to be expressed in financial terms, i.e. the business case.
A good technique to justify IT Infrastructure improvements is to quantify the total cost to the organisation of an IT Service failure(s). These costs can then be used to support a business case for additional IT Infrastructure investment and provide an objective 'cost versus benefit' assessment.
Figure 8.18 is a sample calculation that can be used to quantify the costs associated with IT Service failure:

Figure 8.18 - Example calculation for the cost of an outage
| Hints and Tips Consider undertaking this exercise 'once only' to deliver what the business and IT organisation agree is an indicative cost of failure for a single or range of time periods, e.g.: The cost of one hours peak SLA outage = £xx. The cost of a full day SLA outage = £yy. This then enables an indicative cost to be assigned to each IT Service failure and included in the regular service reporting. These figures should then be reviewed at least annually. Another approach to obtain an indicative cost of a failure is to take the annual cost to the business of taking the service and simply divide by the number of service hours contracted in the SLA for a year. This gives the IT expenditure cost to the business by hour. |
![]()
At the component level there are a number of metrics that should be defined, measured and reported to provide a truly holistic view on how the component meets the range of Availability criterion, e.g.: -
Within the Availability Management Chapter, a number of Sections refer to the creation of metrics that can be utilised to provide this range of component Availability reporting. A suggested framework for these metrics is described in the remainder of this Paragraph.
The simplest form of measurement is to report the proportion of time that a component is actually available for use by the business within the agreed service time. This is usually expressed as the Availability percentage.
This is a simple method of providing a measurement of Availability for hardware, software application and network components and requires minimal investment in measurement and reporting tools. Consequently many SLAs are constructed with Availability measures based on the Availability percentage (%).
Further basic forms of measurement can be considered to provide information concerning the Availability or non-Availability of an IT component, for example the reporting of downtime to reflect the total amount of time a dependent IT Service was unavailable. This can be represented as:
Where Service Maintenance Objectives (SMO) have been agreed for a given planned maintenance activity the total downtime incurred should be recorded as follows:
This method of recording enables a clear distinction to made between agreed planned downtime and the extended downtime incurred due to deficiencies within the implementation process.
Extended downtime reporting can be used to review Change quality issues with internal and external suppliers and be formally reported as non-compliance within OLA and service contract reporting.
Measures that reflect the overall reliability and maintainability of an IT Service and supporting components can be derived from Incident reporting. These can be represented as:
In addition, Incident based reporting can also enable data to be produced which provides an indication of improving or deteriorating trends:
Please refer to Paragraph 8.9.9 and Figure 8.20 for additional guidance.
![]()
The final word on the quality of the IT Service provided rests with the business. While traditional IT measures may show the '%' SLA target met, this does little to change the feeling of dissatisfaction if IT Service Problems have impacted the business operation.
In Section 8.7, it is recommended that a wide range of measures be produced to reflect Availability from a number of perspectives, the key measures being those that reflect the consequence of IT Availability on the business and User.
This business and User approach to Availability reporting provides a number of benefits:
So how can business and User driven metrics be developed to gain the above benefits? The remainder of this topic provides a number of approaches that can be undertaken.
CFIA is used to help predict and evaluate the impact on IT Availability arising from component failures within the IT Infrastructure design. As shown in Table 8.3, the CFIA matrix used during this activity can be expanded to include fields that can map the number of Users supported by each component.
| Component Description | End Users Affected |
| Host |
1,000 |
| OLTP1 |
750 |
| OLTP2 |
250 |
| Order application |
800 |
| Payments application |
50 |
| Order database |
800 |
| Payments database |
50 |
| Server XYZ |
20 |
| Workstation A |
1 |
Table 8.3 - CFIA matrix denoting the number of Users affected by each component
Thus when a component is unavailable, the number of Users impacted is understood. This can enable Availability calculations to be based on the number of Users impacted and/or amount of lost User processing time:
For new IT Services the requirement for enhanced Availability reporting should be captured in the design phase. It is easier and more cost effective to provide this instrumentation within the application during design than to attempt to retrofit once the IT Service is live. Availability Management requirements should be based on the capture of information that relates to the impact on the vital business functions arising from IT component failure:
A valid technique is to estimate the impact of IT failure against the transaction volumes (related to the vital business functions or User activity) normally processed during the period of failure. The data to base the estimations against should be captured and maintained by Capacity Management:
For organisations unable to justify the costs of more advanced Availability measurement techniques, the use of a daily 'User assessment' is a simple technique that provides a business and User view of IT Availability. In its basic form, this is an agreed set of criteria against which the business can assess IT Availability and service quality in support of their business operation. Each day the business User representative should be contacted for their end-of-day assessment, this could be reported as a GOOD day, ACCEPTABLE day or BAD day. This can be recorded and reported using the 'RAG' (Red, Amber, and Green) method.
This approach can be expanded to enable more specific assessment information to be gathered, e.g. the business can assess a number of categories, e.g. Availability, performance, recoverability and be extended to include other IT Service Management functions, i.e. Service Desk:
Systems Management tools which seek to simulate User activity can be deployed to provide end-to-end Availability reporting (real-time and off-line reports). These tools execute scripts to generate sample transactions and monitor and report on areas such as Availability, performance, throughput etc:
The correlation of Customer complaints received against specific IT failures can provide an indication of true Customer impact and frustration:
For certain businesses a consequence of IT failure may be claims for financial compensation by impacted Customers. An example being for the loss of interest due to delayed or missed payments. This is not restricted to the financial services sector, for example some motorist assistance companies pay compensation (or a penalty) for failing to meet a request for assistance within a set time period:
Where the number of Users impacted by an IT failure is known, this information can be used to report User Availability as:
This can be derived from the CFIA documentation to associate the User population impacted by each Incident with a component failure. An example of such reporting is shown in Table 8.4.
|
Incident No. |
Date |
Time |
Duration |
Incident Description |
Failed Component |
User Impact |
|
|
1 |
01 October |
09:25 |
60
|
Payments database full |
Payments database |
50 |
|
|
2 |
04 October |
12:48 |
25
|
Server hang - rebooted |
Server XYZ |
20 |
|
|
3 |
05 October |
09:56 |
125
|
Host operating system failure |
Host |
1,000 |
|
|
4 |
05 October |
16:40 |
20
|
Fuse blown in power supply |
Workstation A |
1 |
|
|
1,071 |
|||||||
Table 8.4 - Example IT Service reporting to denote User impact per Incident
To enable the reported User impact to reflect User productivity loss, requires the amount of downtime per Incident to be expressed as the total amount of End User Downtime (EUDT). This EUDT needs to reflect the number of Users affected by the Incidents.
This enables the amount of User downtime to be derived which can then optionally be used to report as man-hours or man-days lost productivity. An example of such reporting is shown in Table 8.5, where EUDT is calculated by multiplying the DT by the number of Users impacted.
|
Incident No. |
Date |
Time |
Duration |
Incident Description |
Failed Component |
User Impact |
EUDT
|
|
|
1 |
01 October |
09:25 |
60
|
Payments database full |
Payments database |
50 |
3,000 |
|
|
2 |
04 October |
12:48 |
25
|
Server hang - rebooted |
Server XYZ |
20 |
500 |
|
|
3 |
05 October |
09:56 |
125
|
Host operating system failure |
Host |
1,000 |
125,000 |
|
|
4 |
05 October |
16:40 |
20
|
Fuse blown in power supply |
Workstation A |
1 |
20 |
|
|
230
|
1,071 |
128,520 |
||||||
Table 8.5 - Example IT Service reporting to denote User downtime
To provide a User view of Availability, the basic Availability calculation described in Paragraph 8.9.4 needs to be developed. The Agreed Service Time (AST) and the Down Time values need to be replaced with End-User Processing Time (EUPT) and EUDT.
End-User Availability (EUA) can therefore be calculated in a reporting period based on the following calculation:
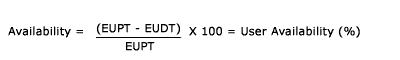
|
Example
|
| Hints and Tips The approaches outlined in this Section should enable a start to be made towards business driven measurement and reporting to complement the existing traditional IT measures. Cost and effort influence the extent to which this kind of reporting is developed. As always the key principle with measurement and reporting applies, in that the cost and effort of producing the measures and reports should not outweigh the benefits. |
![]()
The detailed analysis of service interruptions can identify opportunities to enhance levels of Availability.
SOA is a technique designed to provide a structured approach to identify end-to-end Availability improvement opportunities that deliver benefits to the User. Many of the activities involved in SOA are closely aligned with those of Problem Management. In a number of organisations these activities are performed jointly by Problem and Availability Management.
The high level objectives of SOA are:
The key principles of the SOA approach are that:
The reasons for adopting an SOA approach are:
The benefits from taking an SOA approach are that:
To maximise both the time of individuals allocated to the SOA assignment and the quality of the delivered report a structured approach is required. This structure is illustrated in Figure 8.19 shown below. This approach is similar to many consultancy models utilised within the industry and in many ways Availability Management can be considered as providing via SOA a form of internal consultancy.
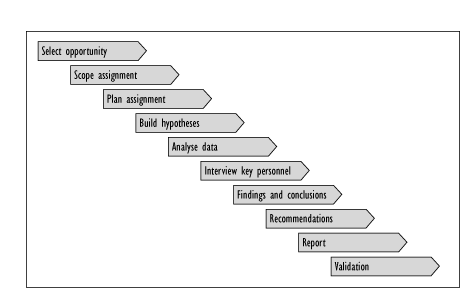
Figure 8.19 - The structured approach for a Systems Outage Analysis assignment
The above high level structure is described briefly as follows: -
Prior to scheduling an SOA assignment there needs to be agreement as to which IT Service or Infrastructure is to be selected. Within the Availability Plan it is recommended that 4 assignments are scheduled per year and if possible the IT Service is selected in advance as part of the proactive approach to Availability Management.
Before commencing with the SOA it is important that the assignment has a recognised sponsor from within the IT organisation and/or the business. This ensures organisational visibility to the SOA and ensures recommendations are endorsed at a senior level within the organisation.
This is to state explicitly what areas are and are not covered within the assignment. This is normally be documented in a Terms of Reference issued prior to the assignment.
The assignment needs to be planned a number of weeks in advance of the assignment commencing. The typical areas that require advance planning are:
The SOA assignment should be looking at identifying improvement opportunities that benefit the User. It is therefore important that an end-to-end view of the data and MIS requirements is taken. A suggested list of data sources is as follows:
For practical reasons the coverage period for the above should be limited to approximately 6 months. This limits the amount of data to analyse but, importantly, ensures that only current issues are being investigated.
To support the team with analysis, supporting documentation should be available to the team, e.g. operational procedures, process documentation, IT policies, configuration diagrams, Industry best practice reference material, e.g. ITIL.
This is a useful method of building likely scenarios, which can help the study team draw early conclusions within the analysis period. These hypotheses can be built from discussing the forthcoming assignment with key roles, e.g. Senior Management, Problem Management, Change Management, and Service Level Management or by using the planning session to brainstorm the list by the assembled team.
The completed hypotheses list should be documented and input to the analysis period to provide some early focus on data and MIS that match the individual hypotheses.
It should be noted that this approach also eliminates perceived issues, i.e. no data or MIS substantiates what is perceived to be a service issue.
| Example If an SOA was planned to review Availability for a Call Centre based IT Service; it is likely that system performance is crucial. Hypotheses to help assess if performance issues are impacting the User Availability could be based on the following: - 'Performance issues are the single largest cause of “Service Unavailability” Incidents impacting Call Centre operation'. 'Existing system and performance monitors do not enable “Service Unavailability” Incidents to be identified, diagnosed and resolved effectively'. |
The number of individuals that form the SOA team dictates how to allocate specific analysis responsibilities.
During this analysis period the hypotheses list should be used to help draw some early conclusions.
It is essential that key business representatives and Users are interviewed to ensure the business and User perspective is captured. It is surprising how this dialogue can identify quick win opportunities as often what the business views as a big issue can be addressed by a simple IT solution.
The study team should also seek input from key individuals within the IT support organisation to identify additional problem areas and possible solutions which can be fed back to the study team.
The dialogue also helps capture those issues that are not easily visible from the assembled data and MIS reports.
After analysis of the data and MIS provided, interviews and continual revision of the hypothesis list, the study team should be in a position to start documenting initial findings and conclusions.
It is recommended that the team meet immediately after the analysis period to share their individual findings and then take an aggregate view to form the draft findings and conclusions.
It is important that all findings can be evidenced by facts gathered during the analysis. During this phase of the assignment it may be necessary to validate finding(s) by additional analysis to ensure the SOA team can back up all findings with clear documented evidence.
After all findings and conclusions have been validated the SOA team should be in a position to formulate recommendations. In many cases the recommendations to support a particular finding are straightforward and obvious.
However, the benefit of bringing a cross functional team together for the SOA assignment is to create an Environment for innovative 'think outside of the box' approaches. The SOA assignment leader should facilitate this session with the aim of identifying recommendations that are practical and sustainable once implemented.
The final report should be issued to the sponsor with a management summary. Reporting styles are normally determined by the individual organisations.
It is important that the report clearly shows where Availability loss is being incurred and how the recommendations address this. If the report contains many recommendations an attempt should be made to quantify the Availability benefit of each recommendation together with the estimated effort to implement.
This enables informed choices to be made on how to take the recommendations forward and how these should be prioritised and resourced.
It is recommended that for each SOA, key measures that reflect the business and User perspectives prior to the assignment are captured and recorded as the 'before' view.
As SOA recommendations are progressed the positive impacts on Availability should be captured to provide the 'after' view for comparative purposes. Where anticipated benefits have not been delivered this should be investigated and remedial actions taken.
| Hints and Tips Consider categorising the recommendations under the following headings: - AVOIDANCE Recommendations that if implemented will eliminate this particular cause of IT Service interruption. MINIMISE Recommendations that if implemented will reduce the User impact from IT Service interruption, e.g. recovery and/or restoration can be enhanced to reduce impact duration. DETECTION Recommendations that if implemented will provide enhanced reporting of key indicators to ensure underlying IT Service issues are detected early to enable a proactive response. |
Having invested time and effort in completing the SOA assignment it is important that the recommendations once agreed by the sponsor are then taken forward for implementation.
The best mechanism for achieving this is by incorporating the recommendations as activities to be completed within the Availability Plan or SIP.
It is recommended that these activities are also managed and tracked by Programme Management, Project Management and Change Management processes.
The team should consist of experienced IT practitioners selected from a range of areas within the IT organisation.
For example the SOA team could consist of individuals from the following functions:
The size of the team should be influenced by the size of the IT organisation and the topic selected for the SOA. A team of at least three is the recommended minimum.
The focus of the SOA assignment determines which of the above it may be advisable to include or schedule within the assignment plan.
As scheduled events, the Availability Management process owner should have these events defined within the Availability Plan and identified Resources committed in advance.
SOA should be viewed as a key element of the Availability Plan that underpins the Availability Management process. Measures should be established to monitor the effectiveness of SOA as an organisational activity and in optimising service Availability.
To measure the effectiveness of each SOA the following metrics could be used: -
The above measures provide a clear indication on how progress is being made with each completed SOA assignment. The number of recommendations rejected may reflect the quality of recommendations made. Conversely a high completion rate would indicate the 'do-ability' of the recommendations made.
![]()
A guiding principle of Availability Management is to recognise that it is still possible to gain Customer satisfaction even when things go wrong. One approach to help achieve this requires Availability Management to ensure that the duration of any Incident is minimised to enable normal business operations to resume as quickly as is possible.
Availability Management should work closely with Incident Management and Problem Management in the analysis of UnAvailability Incidents.
A good technique to help with the technical analysis of Incidents affecting the Availability of components and IT Services is to take an Incident 'lifecycle' view.
Every Incident passes through several major stages. The time elapsed in these stages may vary considerably. For Availability Management purposes the standard Incident 'lifecycle' as described within Incident Management has been expanded to provide additional help and guidance particularly in the area of 'designing for recovery'. Figure 8.20 illustrates the expanded Incident 'lifecycle'.
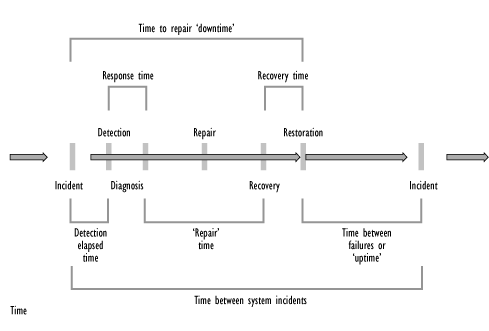
Figure 8.20 - The expanded Incident 'lifecycle'
From the above it can be seen that an Incident can be broken down into stages which can be timed and measured. These stages are described as follows:
Each stage, and the associated time taken, influences the total downtime perceived by the User. By taking this approach it is possible to see where time is being 'lost' for the duration of an Incident, e.g. the service was unavailable to the business for 60 minutes, yet it only took 5 minutes to apply a fix, where did the other 55 minutes go?
Using this approach identifies possible areas of inefficiency that combine to make the loss of service experienced by the business greater than it need necessarily be. These could cover areas such as poor automation (alerts, automated recovery etc.), poor diagnostic tools and scripts, unclear escalation procedures (which delay the escalation to the appropriate technical support group or supplier), or lack of comprehensive operational documentation.
Availability Management needs to work in close association with Incident and Problem Management to ensure repeat occurrences are eliminated.
It is recommended that these measures are established and captured for all Incidents. This provides Availability Management with metrics for both specific Incidents and trending information. This information can be used as input to SOA assignments, Service Improvement Programmes and regular Availability Management reporting and provide an impetus for continuous improvement activity to pursue cost effective improvements.
It can also enable targets to be set for specific stages. While accepting that each Incident may have a wide range of technical complexity, a number of stages should be expected to be consistent and reflect consistency in how the IT support organisation responds.
![]()
The primary purpose of the Availability Management process is to ensure that the Availability requirements agreed with the business for IT Service(s) are consistently met. It is the responsibility of Availability Management to ensure that corrective actions are being progressed to address any shortfalls in meeting the levels of Availability required and expected by the business.
Availability Management can also play a key role in further optimisation of the existing IT Infrastructure to provide improved levels of Availability at a lower cost when Availability requirements change.
The Availability Management process should wherever possible contribute activities to support an overall SIP.
To help achieve these aims Availability Management needs to be recognised as a leading influence over the IT support organisation to ensure continued focus on Availability and stability of the IT Infrastructure.
As the 'champion' for Availability in the IT organisation the function should embrace and engender the ethos of 'continuous improvement' within the IT support organisation.
Continuous Improvement is a key element of 'Quality Management' utilised to empower staff to drive improvements that benefit the business and User. There are a number of Quality Management methodologies available, e.g. Total Quality Management (TQM), however 'continuous improvement' can be embraced without the need for an organisation to adopt a Quality Management methodology.
The 'continuous improvement' methodology can be employed as a technique by Availability Management to facilitate improvements that can be progressed by the IT support organisation to deliver Availability improvements that benefit the business and User.
Availability Management can provide the IT support organisation with a real business and User perspective on how deficiencies within the IT Infrastructure and the underpinning process and procedures impact the business operation and ultimately their Customers.
The use of business-driven metrics can demonstrate this impact in real terms and importantly also help quantify the benefits of improvement opportunities.
Availability Management can play an important role in helping the IT support organisation recognise where they can add value by exploiting their technical skills and competencies in an Availability context. The continuous improvement technique can be used by Availability Management to harness this technical capability. This can be used with either small groups of technical staff or a wider group within a workshop environment.
The basic steps of the continuous improvement methodology are described in Figure 8.21.
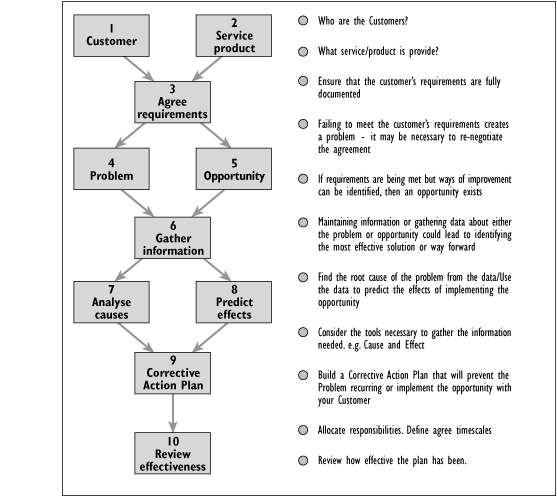
Figure 8.21 - Example of a continuous improvement methodology
The wider benefits of adopting this approach within the IT support organisation are that it:
![]()
Continuous improvement is an ethos fundamental to all Service Management processes and Service Management as a whole. An alternative approach for progressing continuous improvement opportunities is the establishment of a Technical Observation Post (TOP).
The TOP is best suited for delivering proactive business and User benefits from within the real-time IT environment.
A TOP is a prearranged gathering of specialist technical support staff from within the IT support organisation brought together to focus on specific aspects of IT Availability. Its purpose being to monitor events, real-time as they occur, with the specific aim of identifying improvement opportunities or bottlenecks which exist within the current IT Infrastructure.
A wide range of systems management products and tools are available to provide real-time and retrospective analysis on specific aspects of components within the IT Infrastructure. Some are better than others. However, to acquire a global end-to-end view of the IT Infrastructure or a given IT Service using real-time monitors or historical data can often be difficult, time consuming and require significant effort.
Another consideration is the reality that the people who design and support IT systems are not the people who run and operate them. Assumptions and misunderstandings can occur between both parties which unconsciously result in inefficient operational processes, e.g. how many IT support staff actually observe and understand the overnight application processing lifecycle and the key operational events?
Bringing together specialist technical staff to observe specific activities and events within the IT Infrastructure and operational processes creates an environment to identify improvement opportunities.
The scope of a TOP can be wide ranging but must be focused with an overall objective set.
| Example A TOP is convened with an objective to 'Improve the efficiency of the overnight batch window'. The areas to focus on to identify contributory improvements to the TOP objective could include: batch scheduling • batch restart and recovery procedures • automation • application performance • Infrastructure performance • operational processes and procedures. |
A TOP can be convened at any time where this approach is considered appropriate and its Invocation would be planned and scheduled by Availability Management.
The provision of a small area or room with terminals that enables the cross-functional team of specialist technical staff to work together is an important success factor that ensures:
Availability Management as sponsors of the TOP should play a facilitation role providing guidance and ensuring the team remains focused on the TOP objective(s). The role should also ensure that all observations and outline recommendations are captured and subsequently create an action plan that forms part of either the Availability Plan or the appropriate SIP.
The benefits of using a TOP as an approach to continuous improvements are that it:
| Industry view An organisation had failed to recognise the early warning signs of gradual erosion of the overnight 'batch window'. A steady decline in overnight batch processing completion times resulted in SLAs for key services being regularly breached at start of day. The factors behind this increase in elapsed time were difficult to identify after the event, so the decision was taken to form a TOP in order to observe the batch real time. In this particular case, the TOP ran for several consecutive nights, producing recommendations each evening for progression (wherever possible) during the following working day. A daily report detailing both observations and recommendations was created on a daily basis. By the end of the TOP, over fifty opportunities for improvement had been identified and many implemented. The initial 'quick win' actions taken resulted in a reduction in overnight batch elapsed times such that the workload could now be completed within the SLA. As a result of completing all the main recommendations from the TOP exercise, the overnight batch processing elapsed time was reduced by almost 4 hours. |
![]()
![]()
![]()