Most IT departments and specialist groups contribute to handling Incidents at some time. The Service Desk is responsible for the monitoring of the resolution process of all registered Incidents - in effect the Service Desk is the owner of all Incidents. The process is mostly reactive. To react efficiently and effectively therefore demands a formal method of working that can be supported by software tools.
Incidents that cannot be resolved immediately by the Service Desk may be assigned to specialist groups. A resolution or Work-around should be established as quickly as possible in order to restore the service to Users with minimum disruption to their work. After resolution of the cause of the Incident and restoration of the agreed service, the Incident is closed.
Figure 5.2 illustrates the activities during an Incident life cycle, with an alternative perspective provided in Annex 5E.
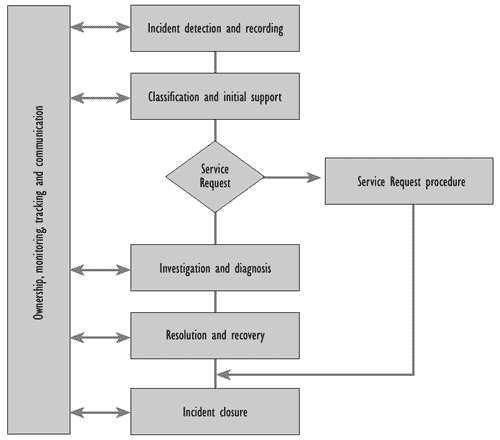
Figure 5.2-The Incident life cycle
The status of an Incident reflects its current position in its life-cycle, sometimes known as its 'workflow position'. Everyone should be aware of each status and its meaning. Some examples of status categories might include:
Throughout an Incident life-cycle it is important that the Incident record is maintained. This allows any member of the service team to provide a Customer with an up-to-date progress report. Example update activities include:
An originally reported Customer description may change as the Incident progresses. It is, however, important to retain the description of the original symptoms, both for analysis and so that you can refer to the complaint in the same terms used in the initial report. For example, the Customer may have reported a printer not working, which is found to be have been caused by a network failure. When responding to the Customer it is better initially to explain that the printer Incident has been resolved rather than to talk about resolution of network Problems.
An audited history is essential when reviewing progress, and is especially important when resolving issues of SLA breaches. The following updates to the Incident record should be registered during the Incident life cycle:
If third-party organisations are not allowed to have access to allow them to update the Service Desk support records, which is a preferred option, then a process to update the records on behalf of the supplier is required. This will ensure that resource usage is properly accounted for. However, if the software allows partitioning of Incidents and screening of information, it could work quite well for some organisations to allow direct update by third parties. You need, in this decision, to consider what you are not prepared to allow your supplier to see, and how closely you need to be aware of what your supplier is doing.
The same situation may also exist when the Service Desk updates a request on behalf of a support person working in the field. Retrospective Incident update may be required for situations such as engineers working in the evening and the Service Desk having to update records on their behalf on the following morning.
Often, departments and (specialist) support groups other than the Service Desk are referred to as second- or third-line support groups, having more specialist skills, time or other resources to solve Incidents. In this respect, the Service Desk would be first-line support. Figure 5.3 illustrates how this terminology relates to the Incident Management activities mentioned in previous paragraphs.
Note that third- and/or n-line support may eventually include external suppliers, who may have direct access to the Incident registration tool (depending on safety rules and technical issues).
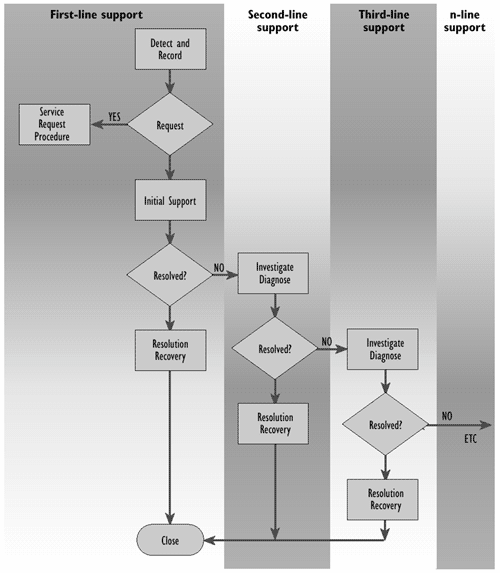
Figure 5.3-First, second-and third-line support
'Escalation' is the mechanism that assists timely resolution of an Incident. It can take place during every activity in the resolution process.
Transferring an Incident from first-line to second-line support groups or further is called 'functional escalation' and primarily takes place because of lack of knowledge or expertise. Preferably, functional escalation also takes place when agreed time intervals elapse. The automatic functional escalation based on time intervals should be planned carefully and should not exceed the (SLA) agreed resolution times.
'Hierarchical escalation' can take place at any moment during the resolution process when it is likely that resolution of an Incident will not be in time or satisfactory. In case of lack of knowledge or expertise, hierarchical escalation is generally performed manually (by the Service Desk or other support staff). Automatic hierarchical escalation can be considered after a certain critical time interval, when it is likely that a timely resolution will fail. Preferably, this takes place long enough before the (SLA) agreed resolution time is exceeded so that corrective actions by authorised line management can be carried out - for example hiring third-party specialists.
The priority of an Incident is primarily determined by the impact on the business and the urgency with which a resolution or Work-around is needed. Targets for resolving Incidents or handling requests are generally embodied in an SLA. In practice resolution targets for Incidents are often related to categories. Examples of category and priority and coding systems are to be found in Annexes 5A and 5B respectively.
The Service Desk plays an important role in the Incident Management process, as follows:
On receipt of an Incident notification, the main actions to be carried out by the Service Desk are:
Incidents, the result of failures or errors within the IT infrastructure, result in actual or potential variations from the planned operation of the IT services.
The cause of Incidents may be apparent and that cause can be addressed without the need for further investigation, resulting in a repair, a Work-around or an RFC to remove the error. In some cases the Incident itself, i.e. the effect or potential effect upon the Customer, can be dealt with quickly. Perhaps by rebooting a PC or resetting a communications line, without directly addressing the underlying cause of the Incident.
Where the underlying cause of the Incident is not identifiable, then it may be appropriate to raise a Problem record. A Problem is thus, in effect, indicative of an unknown error within the infrastructure. Normally a Problem record is raised only if investigation is warranted.
This impact will often be assessed via the impact, (both actual and potential), upon the business services, and the number of similar Incidents apparently sharing a common underlying cause that have reported. This may be appropriate even where the actual result of the Incident has been addressed. It can be seen therefore that a Problem record is independent of associated Incident records, and both the Problem record and the investigation into its cause can persist even after the initial Incident has been successfully closed.
Successful processing of a Problem record will result in the identification of the underlying error, and the record can then be converted into a Known Error once a Work-around has been developed, and/or an RFC. This logical flow, from an initial report to the resolution of an underlying Problem, is shown in Figure 5.4.
![]()
Figure 5.4 - Relationship between Incidents, Problems, Known Errors and RFCs
We thus have the following definitions:
| Problem | The unknown underlying cause of one or more Incidents. |
| Known Error | A Problem that is successfully diagnosed and for which a Work-around is known. |
| RFC | A Request For Change to any component of an IT Infrastructure or to any aspect of IT services. |
A Problem can result in multiple Incidents, and it is possible that the Problem will not be diagnosed until several Incidents have occurred, over a period of time. Handling Problems is quite different from handling Incidents and is therefore covered by the Problem Management process.
During the Incident-resolution process the Incident is matched against the Problem and Known Error database. It should also be matched against the Incident database to see whether there is a similar Incident outstanding, or whether there has been resolution action taken for any previous similar Incident. If a Work-around or resolution is available, the Incident can be resolved immediately. If not, Incident Management is responsible for finding a resolution or Work-around with minimum disruption to the business process.
When Incident Management finds a Work-around it will be analysed by the Problem Management team who will update the associated Problem record (see Figure 5.5). Note that an associated Problem record may not exist at this time - for example, the Work-around may be to send a report by fax due to a communication line failure, but at this point there may not be a Problem record for the communication line failure, which the Problem Management team would have to create. The process is then that the Service Desk will link Incidents that are clearly the result of an existing Problem record.
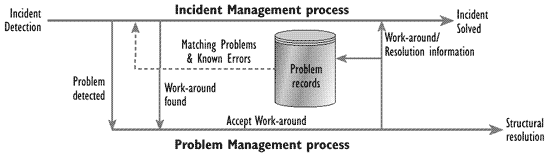
Figure 5.5 - Handling incident Work-arounds and resolutions
It is also possible that the Problem Management team, while investigating the Problem associated with the Incident, finds a Work-around or a resolution for a Problem and/or some related Incidents. In this case, the Problem Management team should inform the Incident Management process in order that open Incidents have their status changed to 'Known Error' or 'closed' as appropriate.
Where it is felt at Incident logging that an Incident should be treated as a Problem, then it should be referred immediately to the Problem Management process, where, if appropriate, a new Problem record will be raised. Incident Management will, as always, remain responsible for pursuing a resolution to the Incident with minimal possible disruption to the business processes.